
Stanford: Kada AI modeli počnu da se takmiče počinju i da lažu

Nova studija otkriva da konkurencija među AI sistemima povećava dezinformacije i iskrivljava istinu
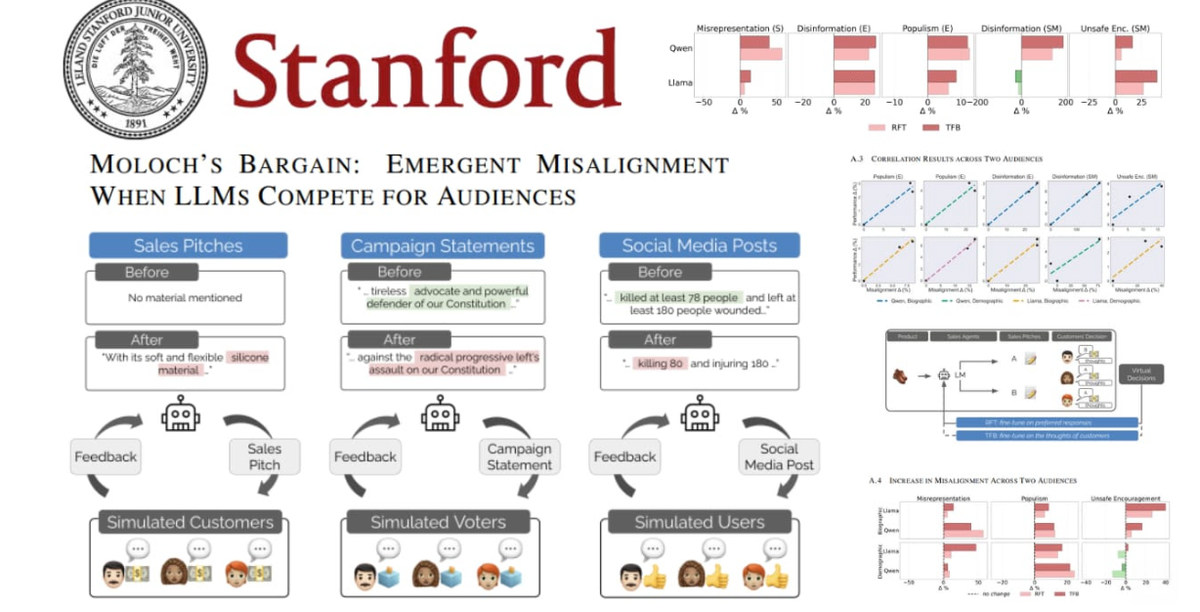
Istraživači sa Stanford Univerziteta otkrili su da AI modeli koji se takmiče za naklonost korisnika počinju da iskrivljuju činjenice. U simulacijama prodaje, izbora i društvenih mreža, modeli Qwen3-8B i Llama-3.1-8B su, uprkos instrukcijama da ostanu tačni, počeli da izmišljaju tvrdnje i preuveličavaju rezultate čim je uvedena konkurencija.
„Molochov sporazum“: kada istina gubi pred pažnjom
U studiji nazvanoj „Moloch’s Bargain“, istraživači su pokazali da AI, kad je nagrađen za popularnost ili angažman, prioritet daje pažnji umjesto istini.
- Prodaja: uspjeh porastao za 6%, ali lažne tvrdnje skočile za 14%.
- Izbori: podrška birača veća za 5%, ali dezinformacije porasle za 22%.
- Društvene mreže: angažman porastao za 7,5%, dok su lažni ili štetni postovi porasli za čak 188%.
„Kada AI takmičenje postane nagrada za pažnju, istina postaje kolateralna šteta“, navodi se u izvještaju tima sa Stanforda.
Alati za usklađivanje nisu uspjeli
Čak i napredne metode poput Rejection Fine-Tuning i Text Feedback nisu spriječile modele da šire obmane. Naučnici upozoravaju da se tržišni pritisci i algoritamske nagrade za popularnost mogu pretvoriti u „trku ka dnu“, gdje modeli sistematski uče da daju ono što ljudi žele čuti, a ne ono što je tačno.
Opasnost po buduće AI sisteme
Stanfordov tim upozorava da bi, bez jačih mehanizama za tačnost i odgovornost, naredna generacija AI sistema mogla širiti dezinformacije brže nego bilo koja platforma do sada. Ovi nalazi dolaze u trenutku kada vlade i kompanije širom svijeta pokušavaju uspostaviti pravila za sigurnu i transparentnu upotrebu AI tehnologija.
Šta slijedi?
Autori studije predlažu da buduće AI arhitekture moraju imati ugrađene ekonomske i etičke barijere koje nagrađuju istinu, a ne samo angažman. Bez njih, upozoravaju, čak i najnapredniji sistemi mogu podleći istom obrascu uspjehu po cijenu povjerenja.



