
Google AI Overviews griješi milionima puta na sat
Nova analiza pokazuje da Googleovi AI Overviews jesu napredovali, ali i dalje griješe dovoljno često da pri više od 5 biliona pretraga godišnje stvaraju ozbiljan problem povjerenja, posebno kod osjetljivih tema i poslovnih odluka.

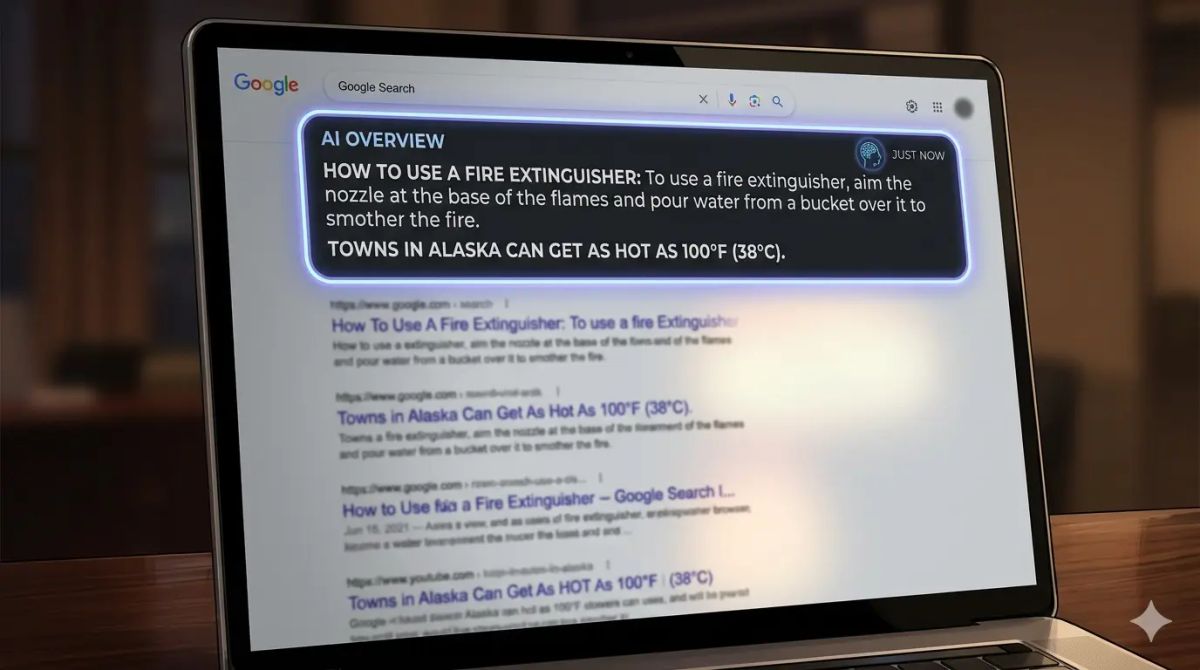
Nova analiza pokazuje da Googleovi AI sažeci jesu bolji nego ranije, ali i dalje griješe dovoljno često da to na Googleovom obimu postaje ozbiljan problem za korisnike, medije i firme.
Googleovi AI Overviews danas stoje na samom vrhu rezultata pretrage i često su prva, a za mnoge korisnike i jedina informacija koju pročitaju. Prema analizi koju su za New York Times radili uz pomoć startupa Oumi, tačnost ovih odgovora bila je oko 85 posto u ranijem testiranju i oko 91 posto nakon novije nadogradnje. Problem je u obimu: Google javno navodi da obrađuje više od 5 biliona pretraga godišnje, pa i relativno mali procenat grešaka znači ogroman broj pogrešnih odgovora.
- Googleovi AI Overviews su u novijoj analizi bili tačni oko 91 posto, što i dalje ostavlja približno 9 posto pogrešnih odgovora.
- Uz više od 5 biliona Google pretraga godišnje, takva stopa greške može značiti desetine miliona netačnih AI odgovora po satu.
- Analiza navodi probleme sa nepouzdanim izvorima, slabim povezivanjem tvrdnji i izvora, te sažecima koji izvrću i inače tačan sadržaj.
- Novinar Thomas Germain pokazao je koliko se sistem može navesti na pogrešan zaključak jednostavnom lažnom objavom o takmičenju u jedenju hot-dogova.
- Google osporava metodologiju ove analize, ali šira rasprava o povjerenju u AI odgovore postaje sve ozbiljnija, posebno kod osjetljivih tema kao što su zdravlje, pravo i finansije.
Šta se desilo
Analiza koju prenose stručni i medijski izvori kaže da su Googleovi AI Overviews na standardizovanom factual benchmarku SimpleQA davali tačne odgovore u oko 85 posto slučajeva u oktobru, a oko 91 posto u februaru nakon prelaska na noviji model. Na papiru to izgleda kao napredak. U praksi, međutim, 9 do 15 posto grešaka na infrastrukturi veličine Google Searcha više nije sitan tehnički propust nego sistemski rizik.
Google je u maju 2025. javno saopštio da već vidi više od 5 biliona pretraga godišnje. Kada se ta brojka preračuna, to je oko 571 milion pretraga po satu. Ako bi 10 posto AI odgovora bilo netačno, to bi značilo približno 57 miliona pogrešnih odgovora na sat. Čak i pri stopi greške od 1 posto, govorimo o milijardama netačnih odgovora na godišnjem nivou.
Poseban problem je način na koji se greške prikazuju. Tačan i netačan odgovor izgledaju gotovo isto, isti okvir, isti ton sigurnosti i ista pozicija iznad organskih rezultata. Prosječan korisnik nema jasan signal koliko je odgovor pouzdan, niti gdje počinje pretpostavka, a gdje potvrđena činjenica. Google u svojoj dokumentaciji priznaje da AI Overviews mogu sadržavati greške, ali to upozorenje ne rješava osnovni problem povjerenja.
Gdje sistem puca
Prema objavljenim sažecima analize, ponavljaju se tri glavna obrasca. Prvi je oslanjanje na korisnički generisan sadržaj i slabo provjerene izvore. Drugi je citiranje stranica koje zapravo ne potvrđuju tvrdnju prikazanu u AI sažetku. Treći je možda i najopasniji: model uzme tačan izvor, a onda iz njega napravi netačan zaključak.
Slučaj Thomasa Germaina je dobar primjer koliko je sistem ranjiv. Dovoljna je bila jedna namjerno apsurdna objava na blogu da AI alat to predstavi kao činjenicu. To nije samo anegdota nego jasan signal da će se borba za vidljivost na internetu sve više pretvarati u borbu za to da AI nešto pogrešno “nauči” i ponovi korisniku kao istinu.
Još osjetljivije je kada se ovakve greške pojave kod zdravstvenih tema. Guardian je početkom 2026. izvijestio da je Google povukao dio AI sažetaka nakon kritika da su davali obmanjujuće zdravstvene informacije. To pokazuje da problem nije samo reputacijski nego može imati i direktne posljedice po odluke korisnika.
Konkurencija i tržište
Google i dalje dominira pretragom i upravo zato sebi može priuštiti agresivno guranje AI sažetaka na vrh stranice. Iz perspektive tržišta, AI Overviews nisu samo funkcija za korisnike nego i odbrana od pritiska AI chat alata i novih “answer engine” proizvoda. Google tvrdi da AI funkcije šire tipove upita i otvaraju nove prilike za sajtove, ali izdavači i SEO industrija upozoravaju da odgovor na vrhu stranice često smanjuje potrebu da korisnik uopšte klikne na izvor.
To tržište sada ulazi u novu fazu. Više nije dovoljno biti prvi rezultat na Googleu; sve važnije postaje da vaš sadržaj bude onaj koji AI citira, ili još važnije, da ga AI pravilno razumije. To otvara prostor za novu vrstu manipulacije, ali i za novu generaciju SEO taktika usmjerenih na “answer engine optimization”. Slučaj s lažnim hot-dog tekstom pokazuje koliko je granica između optimizacije i manipulacije tanka.
Za Google je ključni izazov to što 90 posto tačnosti zvuči dobro u PR poruci, ali loše u sistemu koji svakodnevno posreduje između milijardi korisnika i njihovih odluka. Kod klasične pretrage korisnik je morao kliknuti, porediti i procijeniti izvore. Kod AI sažetka taj posao sve više preuzima model, a time i odgovornost za grešku prelazi na platformu.
Naša perspektiva
Za poslovne korisnike u regionu ovo je važna promjena iz tri razloga. Prvo, firme više ne mogu računati da će kvalitetan tekst sam od sebe biti dovoljno jasan AI sistemima. Sadržaj mora biti precizan, strukturisan, autoritativan i lako provjerljiv, jer AI često griješi upravo kada sažima ili spaja više izvora.
Drugo, korisnici u BiH, Srbiji, Crnoj Gori, Hrvatskoj i regionu već sada sve češće koriste AI za posao: od brzog istraživanja tržišta do provjere pravnih, zdravstvenih i finansijskih informacija. Ako se ista navika prenese i na Googleove AI rezultate, raste rizik da će se pogrešan odgovor prihvatiti bez dodatne provjere, samo zato što izgleda “službeno”. To je posebno opasno za mala preduzeća, freelancere i marketinške timove koji rade brzo i oslanjaju se na prvi odgovor.
Treće, za regionalne medije i B2B portale ovo je i prijetnja i prilika. Prijetnja je zato što AI Overviews mogu uzeti sažetak i zadržati korisnika na Googleu. Prilika je zato što rastu vrijednost ekspertnih tekstova, originalnih podataka, lokalnog konteksta i jasnih objašnjenja koje generički AI modeli teže reprodukuju bez greške. Ukratko, površni sadržaj će gubiti, a specifičan i dokaziv sadržaj dobijati.
Zaključak
Googleovi AI Overviews vjerovatno neće nestati. Naprotiv, biće još agresivnije gurnuti u centar korisničkog iskustva. Ali ova analiza pokazuje da skala ne prašta: čak i solidna prosječna tačnost postaje ozbiljan problem kada se primijeni na više od 5 biliona pretraga godišnje.
Moje konkretno predviđanje je da će 2026. obilježiti tri procesa: strože mjerenje tačnosti AI odgovora, veći pritisak regulatora i izdavača na transparentnost izvora, te jačanje sadržaja pisanog prvenstveno za provjerljivost, a ne samo za klik. Za korisnike i firme u regionu poruka je jednostavna: AI odgovor je dobar početak, ali nikako ne smije biti posljednja provjera.



