
Stanford i Caltech predstavili teoriju AI grešaka
Istraživači sa Stanforda i Caltecha objavili su prvu sistemsku mapu AI grešaka, otkrivajući fundamentalne slabosti u rezonovanju velikih jezičkih modela i upozoravajući industriju na strukturne rizike.

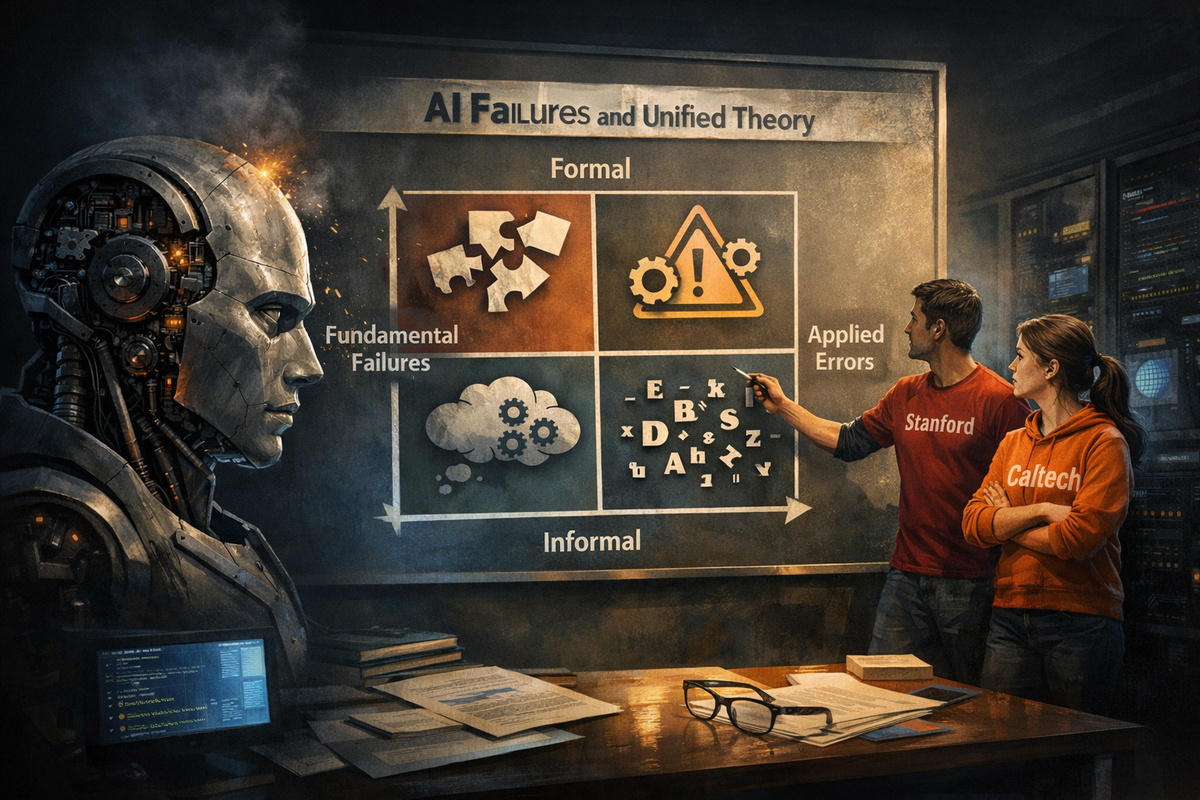
Istraživači mapirali zašto veliki jezički modeli sistematski griješe i otkrili duboke strukturne slabosti.
Istraživači sa Stanford University i California Institute of Technology objavili su prvo sistematsko mapiranje razloga zbog kojih veliki jezički modeli (LLM) griješe. Umjesto liste trik pitanja koja “zbunjuju” model, razvili su dvodimenzionalni okvir za klasifikaciju grešaka u formalnom i neformalnom rezonovanju. Rad pomjera fokus sa pitanja da li AI može razmišljati na pitanje gdje tačno dolazi do pucanja mehanizma.
- Predstavljen je dvodimenzionalni sistem klasifikacije AI grešaka.
- Identifikovan je tzv. “Reversal Curse” modeli ne izvode dosljedno obrnute relacije.
- Male i semantički neutralne promjene u promptu mogu dramatično srušiti performanse.
- Dug lanac rezonovanja često puca zbog problema sa “radnom memorijom”.
- Industrija je upozorena da optimizuje benchmark rezultate, a zanemaruje strukturalnu stabilnost modela.
Analiza: Gdje i zašto dolazi do pucanja modela
Centralni doprinos rada je tzv. two-axis taxonomy, odnosno klasifikacija grešaka prema dvije ose:
- Tip rezonovanja formalno (matematika, logika) naspram neformalnog (jezik, svakodnevni zaključci).
- Klasa greške fundamentalne greške sistema naspram aplikacionih grešaka vezanih za konkretne zadatke.
Reversal Curse
Jedan od ključnih nalaza je fenomen nazvan “Reversal Curse”. Ako je model treniran da zna da je A povezano sa B, često nije u stanju da pouzdano zaključi da je B povezano sa A. Ovaj problem otkriva duboku asimetriju u načinu na koji modeli internalizuju činjenice.
Krhkost na male promjene
Istraživači su pokazali da jednostavno preuređivanje ponuđenih odgovora ili minimalne izmjene formulacije pitanja mogu drastično smanjiti tačnost modela. To ukazuje da modeli često ne razumiju zadatak, već prepoznaju obrasce.
Curenje radne memorije
Kod složenih zadataka sa više koraka dolazi do tzv. “working memory leaks”. Model započne ispravan tok rezonovanja, ali tokom generisanja odgovora izgubi ili pogrešno primijeni ranije korake. Problem nije samo u znanju, već u održavanju konzistentnosti kroz vrijeme.
Konkurencija i stanje na tržištu
U protekle dvije godine, tržište LLM modela fokusirano je na nadmetanje u benchmark rezultatima. Velike firme objavljuju rezultate na testovima poput matematičkih i programerskih zadataka, ali ovaj rad sugeriše da takvi rezultati ne garantuju strukturnu pouzdanost.
Industrija je do sada tretirala AI greške kao izolovane incidente koje treba “zakrpiti” finim podešavanjem. Međutim, nova mapa grešaka pokazuje da su mnogi problemi sistemski, a ne slučajni.
Objavljivanjem javnog repozitorija sa dokumentovanim tipovima grešaka, istraživači praktično pozivaju cijelu industriju da pređe sa kozmetičkih poboljšanja na fundamentalnu stabilnost modela.
Naša perspektiva: Šta ovo znači za region i poslovne korisnike
Za firme u regionu koje koriste AI za:
- automatizaciju korisničke podrške,
- analizu dokumenata i ugovora,
- generisanje marketinškog sadržaja,
- pomoć u programiranju,
ova studija nosi važnu poruku: visoka tačnost na testovima ne znači pouzdanost u realnom poslovnom okruženju.
Ako model ima problem sa obrtanjem relacija ili zaboravlja ranije korake u složenoj analizi, to može proizvesti:
- pogrešne pravne interpretacije,
- netačne finansijske procjene,
- nekonzistentne izvještaje,
- greške u kodu koje se teško uočavaju.
Za poslovne korisnike ključno pitanje više nije “koliko je model pametan”, već “koliko je stabilan pod promjenjivim uslovima”. Ovaj rad pomjera fokus sa impresivnih demo prezentacija na inženjersku pouzdanost.
Zaključak
Istraživanje Stanforda i Caltecha jasno pokazuje da AI greške nisu slučajne, već sistemske. Industrija je trenutno previše fokusirana na kratkoročne benchmark pobjede, dok se zanemaruje kognitivna fleksibilnost i strukturalni integritet modela.
U narednim godinama možemo očekivati pomjeranje tržišta ka modelima koji demonstriraju stabilnost kroz širok spektar zadataka, a ne samo vrhunske rezultate na uskim testovima. Firme koje prve usvoje rigorozne standarde testiranja i validacije imaće značajnu konkurentsku prednost.
Link do istraživanja: https://www.arxiv.org/pdf/2602.06176



